Non-aligned supervision for Real Image Dehazing
arxiv 2023
- Junkai Fan
- Fei Guo
- Jianjun Qian
- Xiang Li
- Jun Li*
- Jian Yang*
- Nanjing University of Science and Technology

The effectiveness of our method on hazy video
Abstract
Removing haze from real-world images is challenging due to unpredictable weather conditions, resulting in misaligned hazy and clear image pairs. In this paper, we propose a non-aligned supervision framework that consists of three networks - dehazing, airlight, and transmission. In particular, we explore a non-alignment setting by utilizing a clear reference image that is not aligned with the hazy input image to supervise the dehazing network through a multi-scale reference loss that compares the features of the two images. Our setting makes it easier to collect hazy/clear image pairs in real-world environments, even under conditions of misalignment and shift views. To demonstrate this, we have created a new hazy dataset called ”Phone-Hazy”, which was captured using mobile phones in both rural and urban areas. Additionally, we present a mean and variance self-attention network to model the infinite airlight using dark channel prior as position guidance, and employ a channel attention network to estimate the three-channel transmission. Experimental results show that our framework outperforms current state-of-the-art methods in the real-world image dehazing.
Method
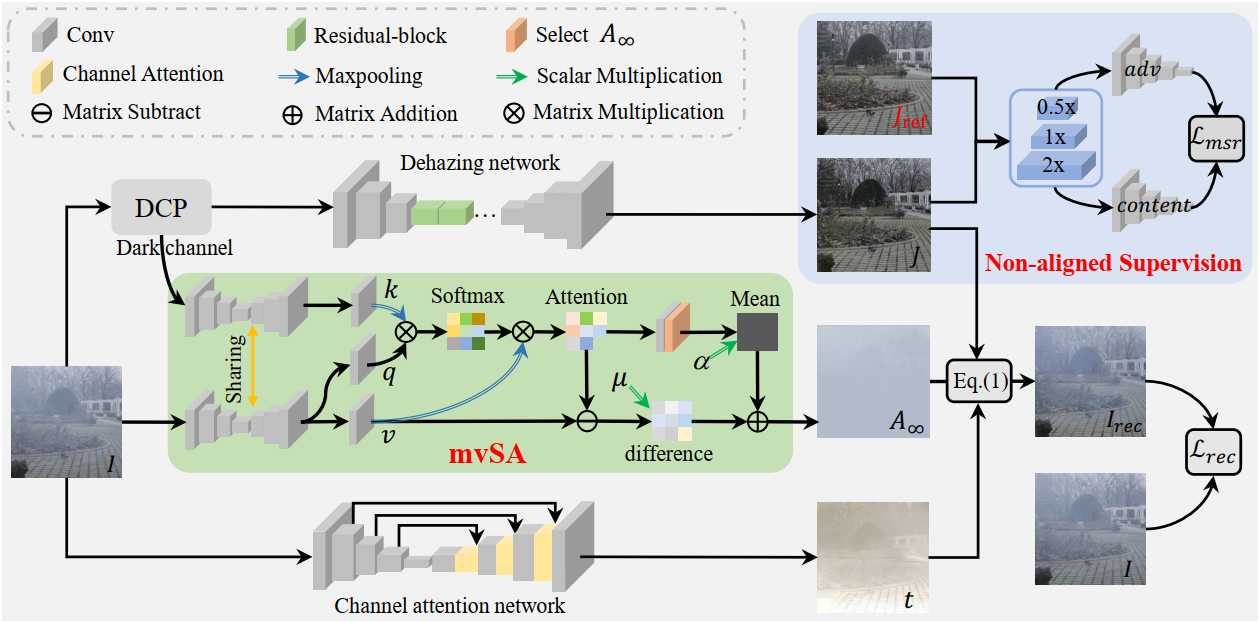
Overall pipeline of our non-aligned supervision framework with physical priors for the real image dehazing. It includes the mvSA and non-aligned supervision modules. mvSA can effectively estimate the infinite airlight A∞ in real scenes. Our framework is different from the supervised dehazing models as it does not require aligned ground truths.
Results

Example results on the real-world non-homogeneous smoke dataset.

Example results on the real-world dense smoke dataset.

Comparison of dehazing results on the real-world Phone-Hazy dataset (rural scenery).

Comparison of dehazing results on the real-world Phone-Hazy dataset (urban roads).

Comparison of dehazing results on the real-world RTTS dataset (wilderness and city buidings).

(a) - (c) shows our model's visual results on the Phone-Hazy dataset, while (d) - (e) shows the visualization of our model's test results on RTTS dataset.
Citation
If you find our work useful in your research, please consider citing:

Acknowledgements
Thanks to Ricardo Martin-Brualla and David Salesin for their comments on the text, and to George Drettakis and Georgios Kopanas for graciously assisting us with our baseline evaluation.
The website template was borrowed from Michaël Gharbi.